https://www.coursera.org/learn/machine-learning/home/welcome
前面幾週都是 supervised learning, 也就是知道因果關係下,去找因 (features) 來解釋這個果 (Y) 。前面二週和我在大學時學的迴歸分析差不多,所以飛快的聽過去。Octave 和線性代數還小小溫習了一下。
以下是上課時的 doodle notes.
第三週
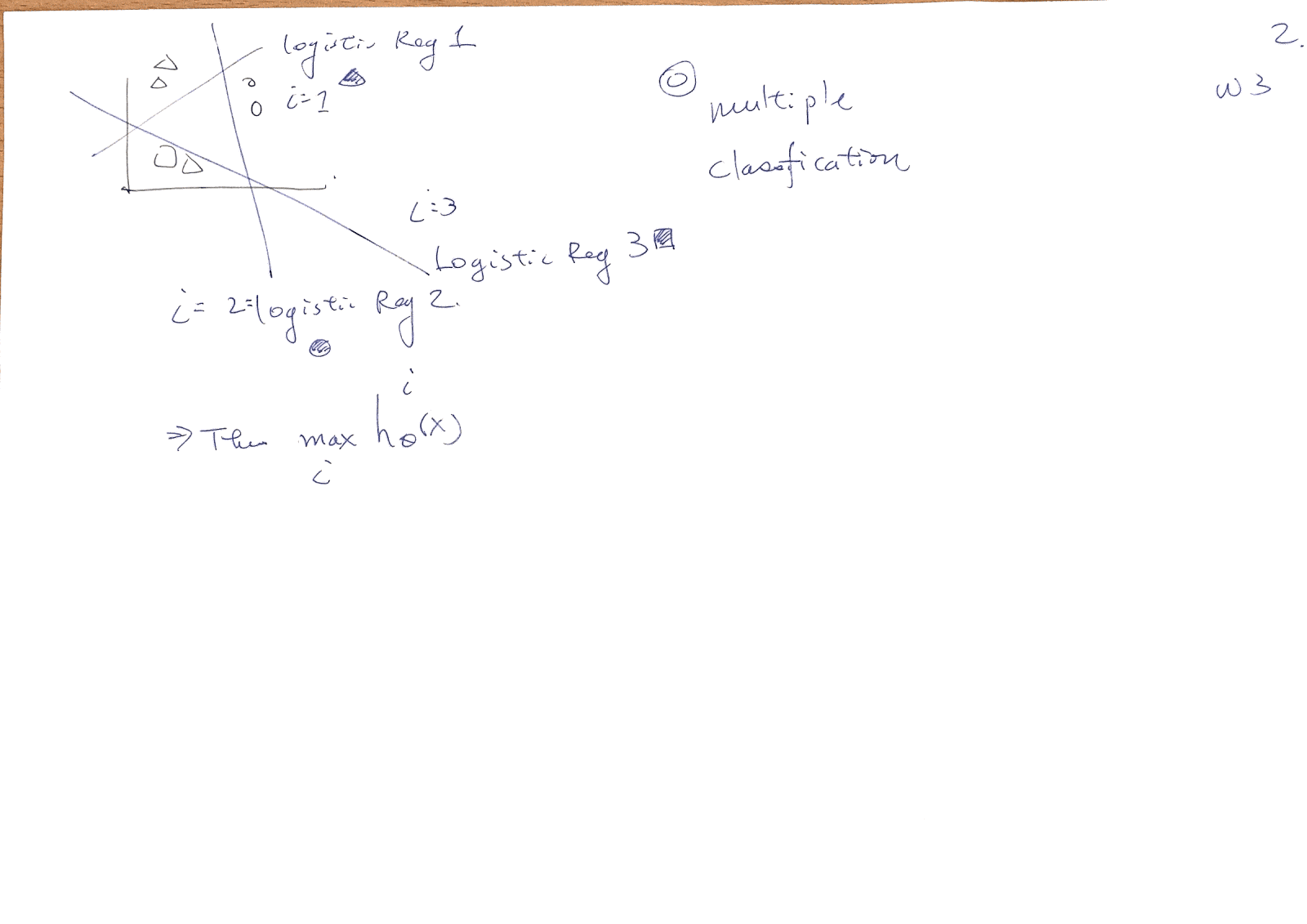
進入 Logistic Regression,Y 這個果的輸出是以類別的方式作輸出。一樣先導出 Cost Function (i.e. 預估和實際值的差別),再以 Gradient Descent 來求解最小的 Cost 。老師先講兩類的作法,再提到多類別 (Multiple Classfication)的作法。多類別基本上就是多種的2類。
接下來進入太過緊身的議題,解釋的因子X太多或者 polyminal 次方項太多,會有 overfitting 的問題。也就是原來的 sample 都能完整的解釋 (i.e. cost 小),但新的 sample 就不太行了 (i.e. cost )。這時就要導入 Generalization 項,基本上就是管一管這些 features 項不要太猖狂,以免太過緊身。

第三週學完,最令人興奮的是,老師說:
。。。 you probably know quite a lot more machine learning right now than frankly, many of the Silicon Valley engineers out there having very successful careers. You know, making tons of money for the companies.聽起來實在振奮人心呀!!!
第四週
開始進入 Neutral Netowork ,個人覺得這是這個課程的大重點,也解釋了我心中的疑問。包含圖形要如何辨識,以及那一層層的 neuron 是在作什麼的。一剛始就大概提一下如何用圖片 pixels 來作辨識 。接下來是重點,為什麼要多層的 hidden neuron? 這兒老師用 XOR,AND 和 XNOR 來解釋。一層的 hidden layer 可以運算出 XOR 和 AND;但 XNOR 就要兩層的 hidden layer 。所以,暝暝中,你就會知到多層 hidden layer 能處理較複雜的 logic 運算。


第五週
皮要緊一點,還真的有點腦筋 twist! 主要是 Neutral 的 optimazation 運算。跟著老師 forward propagation 到最後的 backpropgation 。中間還要作 gradient check, check 完要記得 disable。如此的大費週張,主要當然是要求解 neutral network 的 thetas 。
第六週
Dataset 分成 Training、CV和 testing。先談 Bias 和 Variance 的差別。基本的結論是 bias 就是 error 太大,所以要加 features 來降 error 。加到一定程度後呢? 要加到 CV的 error 勾起來時,就要停手了。接下來就靠樣本數 M的加大,來降 error。所以為什要大數據就很明顯了,因為能降所以結論就是 feature 多加一點降 bias , Variance 太高不用怕,用大數據M來解決!

接下來談到當 data skew 時的判斷法。算命界有個笑話,對來算命的男人說事業失敗,對女人說婚姻不幸,八九不離十。因為來算的多是 true positive 呀。所以老師會教導,如何用 F1

第七週
教另一個 algo ~ SVM (Super Vector Machine) 基本上是像 logistic regression 的東西,但號稱有 large margin, 同時配備 Gaussian kernel 運算,變身為超強的 algo。聽起來神奇又難寫 code , 但別怕,有套裝軟體 liblinear 或 libsvm 可以使用。重點是要會選用參數 C 和 Sigma! 再學坂木浩子的書,作幾個插畫!看來歡樂有趣多了!



第八週
開始進入 unsupervised learning 的領域,就是沒有Y,只有X。如何自動歸類X 來分析,就是很有趣的議題。要分成幾類呢?問問手肘就可知道,這是不是很神奇呢?

Features 要是太多,不只浪費運算資源,自己也對資料無感,這時就要動用 dimensionality reduction,使用 Principal Component Analysis (PCA) 來處理。這時 cotave 的運算式 就要搬出來好好運用。
[U,S,V]= svd (sigma);
用 U 來作簡化 dimension 的運算,同時用 S來看看抓住了多少的 variance。


第九週
除錯,用 Multivariance Gaussian 分配來找出邊緣值 (Anomaly detection) 。這和統記的 P 很像,所以滿直覺的。資料要是不是 Gaussian分配,就需要先處理一下。取 log 或開個多次方,可以變成 Gaussian 分配,好神奇哦! (學簡筆插畫book一書,再畫些圖上去)

接下來是推薦看電影片的系統,利用個偏好的 rating 可以推出電影口味重不重,同時還可以再推斷你沒評偏好的片,神奇的 Collaborative filtering Simutaneously 運算式。

第十週了
。。。咻!資料太大,電腦想一想就當機了,這時要用 Stochastic gradient descent 來漫遊運算,但這個 algo 很愛逛街,明明終點 (global min) 就在前方,他還是在附近打混,所以降 alpha 可以令他離終點近一點。 另一方法就是打群架,多買幾台電腦或多核運算囉。


第十一週
都是應用的東西,我就沒作筆記了,一件問題要先切成幾斷來作,然後千萬不要一下就分配下去作,要先用 ceiling analysis 看要投入多少資源,再火力強大的作有效率的事。最後老師很感幸的謝謝學生上課,實在很感謝老師無保留的教大家這麼多。後記,學完後才發現 Andrew Ng 來頭不小哇,Google 和百度的 Deep Learning 都是他的成果,Coursera 也是 founder!
No comments:
Post a Comment